Introduction
This lesson concludes our discussion over local area networks. We will be discussing how to administrate a local area network, but we will avoid the details. This discussion will cover a large area, and we could discuss this a lot more. I have included links from the homepage of this coarse to more information for those of you who might be interested.
Networks are administered in many different ways, from the most thorough method where everything is well planned and properly documented, and down to the haphazard way where errors are corrected a few days after they occur. We will discuss the two limits, administration using reactive management and proactive administration. These two philosophies are opposites, and no real networks are entirely administrated like these two. But it still might be good to know of such philosophies, to make it easier to make your own administration-philosophy.
This is the last lesson in this class dealing directly on local area networks, and the class could very well be ended here. But there will be a final lesson that will deal with administration of web-servers. This can to a certain degree also be counted as local area network information, since the technology for Intranets is the same as for local area networks.
Administration using reactive management
"The network is down!!!" is an expression a system administrator gets repeated more than anything is. The network being down can mean a number of things.

- A user has made a user-error and the application or the computer "freezes".
- The mail system is out of order, and messages do not arrive.
- All communication with other units (printers, shared harddisks and so on) is lost.
- All the servers "freezes" making everything stop, even the workstations (especially the disk-less ones).
Such down-messages from frustrated users might mean anything from an application error, to a large server or network error. But equal for all errors is that the system administrator has to react. The biggest problem with this method is the reaction part - nothing is done before an error has occurred, and quite possible already caused great harm to the firm. Equality for all errors is the cost (at least working hours) which makes it necessary to correct errors as quickly as possible.
Possible error sources after a network error call might be:
- The users keep doing errors - could more education help?
- The workstations fail - change the set-up of the workstation, or new workstations?
- Servers fail - upgrade if the failure is caused by to low capacity?
- The cables did it! - Change cables that are broken.
- Blame it on the plugs - if the workstations loose connection because of a broken plug, replace it.
- The network adapter had a (nervous) breakdown - Buy a new adapter of better quality
- The WAN won't start - If it is impossible get a connection out of the network, some components might be broken. Fix or replace them.
The first step of error correction is localising the error. This part might prove itself difficult. So let's start with categorising the error. It might be a user-error, software-error, hardware-error, or a cable-failure. If the error can be placed in such a category, it makes it infinitely more easy to point out the problem later on.
After the localisation of an error, it has to be corrected within a reasonable amount of time. "A reasonable amount of time" might vary from time to time. If the business is very dependent on the network, reasonable will be a short period, often within the hour. If this business is a place that uses the network little, and therefore isn't very dependent on it, reasonable might be several days. As I have mentioned several times earlier, the grade of stability, the quality and how quickly the network can be restored, depends on how much resources the business are willing to spend on the network.

Figure 1 - What is an reasonable amount of time?
A good idea is to classify the different types of services a network is supposed to do for the users, and from these classifications calculate the reasonable amount of time depending on classification of the service. An example could be that printer services should be functional two hours, malfunctioning workstations should be operational within the hour, the e-mail system should be working again within eight hours, and backup -units and -system should be online within four hours. Such an specification has to be built upon the needs of the firm towards the network, and these needs has to be prioritised I a way that lets haste-jobs, get in front of smaller less important tasks. Even the administrator's own work has to be incorporated in such a plan to make him able to see what might be down prioritised in case of an emergency. Such a priority list often makes the administrator's job easier, also in his normal work.
Idetifaction and correction - one method
Collecting information
When describing a possible error, finding and solving it seems like an easy task. Everyone who has some experience with administration knows it is not so. Only the task of finding the error might be a big task.
When an error occurs, it is very important to examine every symptom thoroughly. Many of the errors occurring in a network are user-related. The simplest way of localising the error is normally to talk to the user. It is reasonable to ask the user several questions to get a good idea of what happened before the error occurred. Which applications where used? Was this the first time this application or this mix of applications where used, or has this been done more or less successfully before? Did anything special happen just before the error occurred? It is also a good idea to take a look at the user's priority to find out how important it is to get him back online quickly. Everybody is their own centre of the earth, and it is there fore most important to get their workstation back online, but with ten different most important persons, it is good to have a priority list to fall back on.
Before going too far in the investigation of the user, the basic errors have to be eliminated. Giving the computer to many uncontrolled kicks in its network adapter might just cause a lot of harm, a minor error in the setup is also capable of stopping a workstation, or the user might have trouble remembering his password, and there fore have inflicted login restrictions upon himself.
Analyse the information and diagnose the failure
The strategy in this phase is to isolate the problem, and thereafter solve it. For those of you known to programming-algorithms, the binary search should be a well-known sort method.
If we want to sort a list over persons and find the name "Bill Clinton" in the sorted list, we will use the method outlined in figure 2. The list is first sorted, and thereafter split in half. Next we check to see if the name is localised in the upper or lower half. In our case the name is localised in the upper half. The upper half is divide into two and we search the list again to see if the name is in the upper or lower half of the upper half. We still find the name in the upper half, Which is divided into two giving two names in the upper half and one in the lower half. And the name in the lower half seems to be the one we were searching for. For a computer this is an efficient way to search.
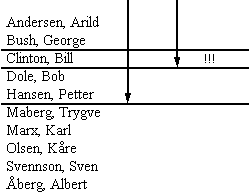
So whatever could binary searches have in common with administration philosophies? When we are seeking for an error, it is convenient to use the binary search pattern. We can split the network into smaller parts, and in this way isolate the parts that either has an error, or are error free ("Lets se… I have a network over two floors… Is the error in the first or the second floor?"). With this method it is possible to isolate single workstations to test them on their own. If the workstation works on its own, it is innocent. Then the cable segments are checked, just to make certain these are not broken. The error might also be in the software, and any suspicious software can be removed to see if the error disappears with them.
Another method is surveillance of the users to discover which errors they
do. This is a very time-consuming process, especially if the administrator has
to run around the network to stand behind every user's shoulder to see what they
might be doing. There do exist administration-software that supports such
surveillance of the users. A package that exists within Windows NT has good
support for remote administration and surveillance; System Management Server.
This software makes it possible for the system administrator to "enter "
a user's workstation and monitor what the user does. The SMS software makes the
administrator able to:
- See the current screen on the users computer
- "Write" on the user's workstation, in other words gain control over it.
- Transfer files to the workstation
- Control the workstations mouse pointer from the administrator's mouse.
- Read memory usage and configuration
- Automatically distribute software.
We can see that such an application might ease the job of a system manager that is supposed to find and remove errors. If the offending workstation is located in another building entirely, the administrator is able to take remote control over the network, and correct the error.
More information about SMS is located at the Microsoft web pages; http://www.microsoft.com/smsmgmt/revgd/sms03.htm.
3.1.3 Solve the problem
When the error is identified, it has to be corrected. In this phase we return to the importance of prioritising the errors (Do you really need to fix that broken harddisk in the server now, or should you go fix that broken floppy disk station down in the heater-department first?).
3.1.4 Documentation
Problems tend to repeat themselves. A keyword when talking about the quality if the administration tasks, is the documentation of everything that is done. If every problem that occurs is properly documented, it makes it easier to fix the error if it should reappear. Especially if the administrator, for some reason, should be changed. If the previous administrator documented everything properly, the predecessors get an easier job when errors should occur or reoccur.
It is a pretty good idea to standardise the documentation (use either old newspapers or used napkins to document those pesky errors, but do not use both! ). If you use a standard report scheme and a standard follow-up scheme, the quality of this important task is not left to the one responsible for the job.
4. Proactive administration
In the previous chapter we discussed the basics of the reactive management, where the error came first, followed by a reaction. Now we will discuss the opposite way to manage a network. The basics of proactive administration is exactly that, preventing errors from happening by always keeping one step ahead of them. We can define proactive work as "to do something to prevent an error before the error has occurred so that the error won't happen" (this is really a self-contradiction). The utopia of proactive administration is to be so far ahead with the administration tasks that errors simply do not occur. But this is completely impossible to do, that is why this theory is presented as a management -philosophy and not a -method.
An example from a similar situation; for a few years ago I owned a car that had increasingly more problems. It could stop at any time, and I had to use a lot of "reactive management" to keep it running. This situation grew gradually worse, and the intervals between the stops got shorter and shorter until one day it stopped in the middle of Trondheim's most trafficked crossroad. This is a good example of the consequence of reactive management of my car, I was without car for a long time while it was in for repairs. If I had read the signs earlier, and reacted upon them, I would have prevented this. I should have used proactive management with my old car.
A network behaves in many ways in the same way. It often deteriorates gradually before finally breaking totally down. We can see a tendency for a breakdown before it happens. Conceptually there are two methods we can use, capacity planning and system tuning.
Capacity planning
The idea of capacity planning is to plan ahead to be able to see eventual changes that comes along, and doing something to be ready for the changes. An example of such changes is adding users to the network, and the changes that have to be made to support this. Buying more workstations is self explanatory, but more interesting is the changes in the workload of the net, and if the net are able to handle this. The network might not have a powerful enough server to handle this, and it might need another disk or more memory, or maybe a new server? In any case more licences for the software in use are needed, both for network licences and for other software. If the software has no support for network use and several users, this has to be arranged.
Adding more users to the network is an important area in capacity planning, but connecting the network to the Internet is an equally large area. If the network mostly where used for printing, internal communication, document sharing, and other normal tasks, The Internet will bring grave consequences for the traffic on the net. The Internet is a "killer" concerning the traffic caused by all its pictures and information.
Even here it is important to think documentation. Those adaptations made from capacity planning have to be thoroughly documented, by the same reasons as earlier.
Tools for capacity planning
There are three main tools that are used for capacity planning. Those are performance monitors, simulator models, and traffic generators.
Performance monitors
This tool measures the performance of a network.
Simulator models
A model of the network is used in connection with this tool. In stead of testing future changes in a real network, they are tested on a model of the network. Such a model gives an answer to expected traffic in the form of response times, processor usage, and cable traffic.
To implement such a model successfully, we depend on correct and accurate information about the network.
Traffic generators
Traffic generators generate artificial traffic on an existing network to simulate expected traffic after an expansion. With traffic generators we simulate the expansion before it is made, and are able to step in front of any probable problems, and upgrade the network before the expansion is done. This type of testing is often called "stress testing".
System-tuning
System tuning means to collect and analyse data about the management of the data. There exist a lot of tools that support such an activity.
4.2.1 Network Management System
One type of tool is placed under the collective term "Network Management System (NMS)". The task for NMS is to
- Collect data about the network; usage, traffic, disk usage, attempts of illegal entries, and so on.
- Analyse management data and statistic-functions that put data in connection overtime.
- Give alerts by extreme values.
Such tools can efficiently and systematically find changes in the usage, which often is an indicator for the possibility of the occurrence of a larger error. The best systems are also able to give advice about how to change the system for the better.
4.2.2 Network analyser
Another tool for use in the system tuning is the network analyser. The network analysers often work on a lower level than the NMS. The network analyser descends into the data communication levels and takes a look at the packet transportation. It analyses the transport of packages, and reports which types of packages are being transported, the number and density of the traffic, and the error rate for the transmissions. The meaning with such tools is to be able to discover if the network is reaching its capacity limits. Advanced analysers also have statistic functions that are able to show us the development over time.
The goal of system tuning is to spot changes in usage, check the error rate (that holds back the communication unnecessary) and to check for usage tops that gives bottlenecks at certain times of the day.
Responding to system tuning
The meaning of system tuning is to get some idea about trouble areas within the network. A natural respond to messages from the tuner software is to fix the errors. Several different things can be done, and we will now discuss a few of them:
- Moving or balancing components. We can imagine a network that, to
make it simple, consists of two segments (Figure 3). One segment is heavily
used, and a bottleneck and the other segment are relatively all right. These
measures are made with a tool for system tuning. Solutions to this might be to
move components over from the more used over to the less used segment. This
makes segment 2 more used, we have just balanced the network. We can just hope
that segment 2 don't become the new bottleneck.
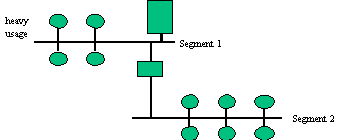
Figure 3 - balancing - Buying new hardware. In the example above another solution might
have been to buy a new server to segment 2 to relieve the segment 1 server from
segment 2. A similar example can be made for printers. If a printer always as a
long queue, it might be smart to move users from one department to another one
that has less usage (or just move some of the users over to another queue), or
install a new printer.
If the measures show too much disk swapping, both for servers and for workstations, it might be a good idea to buy more RAM to relieve the users of this unnecessary waiting period. Such waiting periods often cost more than solving the problem.
Generally, we can say the following about reacting to system tuner results: When we are balancing a system or doing other such drastic measures, it is reasonable to move one component at a time. It is dangerous to reconstruct the entire network in one bite, and still believe it should work. If one component are moved at a time, and properly tested and documented, it should be easy to localise the error if something should fail to work.
Summary- system tuning
Generally I can set up this plan for a system tuning:
- Measure the efficiency of the network, and analyse the statistics.
- Find possible solutions to the problem
- Choose the best solution from the given demands. The demands might be:
- The best result
- The most efficient
- The fastest
- …
- Install and test the chosen solution
- Evaluate
- Measure the efficiency again - if more problems need solving go back to step three.
- Document everything thoroughly!
The article "Where can you find the critical features you need?" discusses four big computer-based administration applications and discusses ups and downs with each. The article is as usual flavoured by the author's opinions.
SNMP - Simple Network Management Protocol
SNMP s a standard (a TCP/IP-protocol) for exchanging administration data related to network administration. One article "An Introduction to SNMP" is added as curriculum to get some technical knowledge about a relatively simple level of the protocol.
The meaning of SNMP is to be able to transmit status signals to components in the network. Among other things it should be able to give some answers if the components are turned on/of, free, busy, … It is also supposed to be able to carry information about errors that occur in the network.
Several of the administration tools discussed in this lesson uses SNMP as a protocol to collect administration data from the entire network.
SNMP will no be discussed any more in this lesson. It is discussed well enough in the article.
Summary
In this lesson we haven't discussed any special network systems at all. We discussed the general principles of administrating a local area network, and how this can be done supervisory. It is important to know of these areas as a system administrator.
We have been discussing two opposing administration philosophies. There exist no networks that entirely are administrated after any of these two methods. The challenge is to find a level of proactive administration that fits the network that you administer.
Finally in this lesson we discussed briefly a protocol for network
administration, SNMP, and an Internet article are added to the curriculum for
this class.